Thanks to the hard work of Niles Zhao, the homo calculans project now possesses a corpus of articles, books and chapters from the early years of the Computational Human Sciences. The field was vaster than either of us expected. When we started the project, I expected that we would be able to get essentially all the articles from the period that reported on computer-enabled research.
Boy was I wrong.
By the mid-1960s, there was already a large community of computational humanists and social scientists, and research methods were rapidly maturing. Experimentalism was rife. Computer power was, it seems, relatively abundant.
In this post, I will just sketch the outlines of the corpus, relying on the metadata Niles has collected about the articles, books, and chapters, and the annotations he has made about research disciplines and the available hardware.
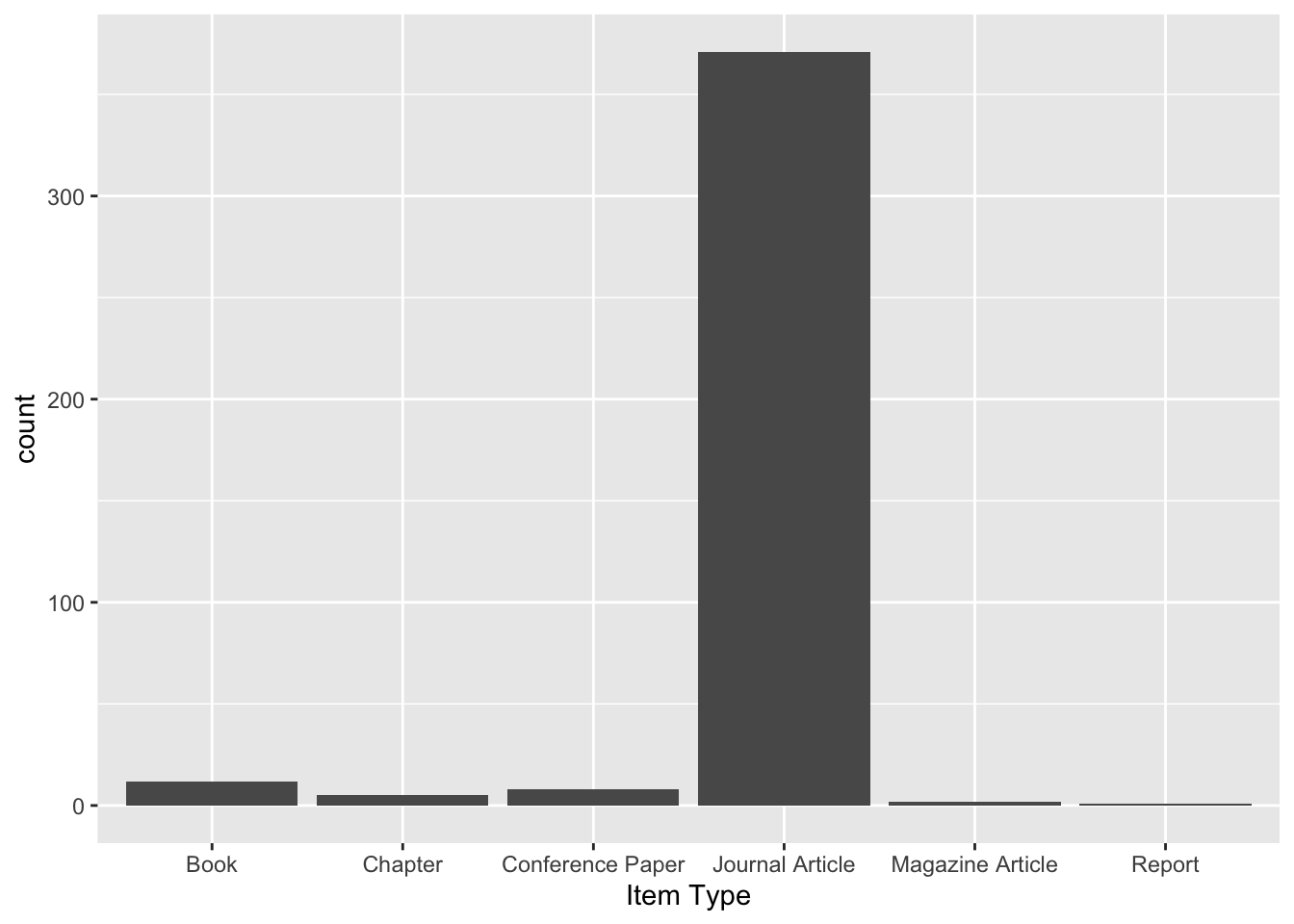
In this present state, the corpus includes 399 academic texts. We have pdfs for 387 of these, though hopefully we will be able to increase this proportion before the project ends. The corpus includes 6 kinds of text, though it is dominated by Journal Articles, as shown in Figure 1.
Figure 1: The items in the corpus are mostly journal articles, as expected.
Which disciplines are represented?
Who was doing this research in the 1950s and 60s? Which disciplines were at the forefront? We were hoping to be able to give crisp, empirical answers to these questions, but the literature turned out to be so large that is has proven hard to sample the population. For now, we can just see which disciplines appear to be represented in the corpus that we have.
Niles tagged the items in Zotero, which is great because it is flexible, but not so great because the tags are unstructured. First we need to sort the tags into two groups: discipline tags and technology tags.
Code
# Get list of tags for categorisationcorpus |> tidyr::unnest(c(tag)) |> dplyr::distinct(tag) |> dplyr::mutate(tag_category ="") |> readr::write_csv("all-tags.csv")# Import categorised tagstag_categories <- readr::read_csv("all-tags-categorised.csv")
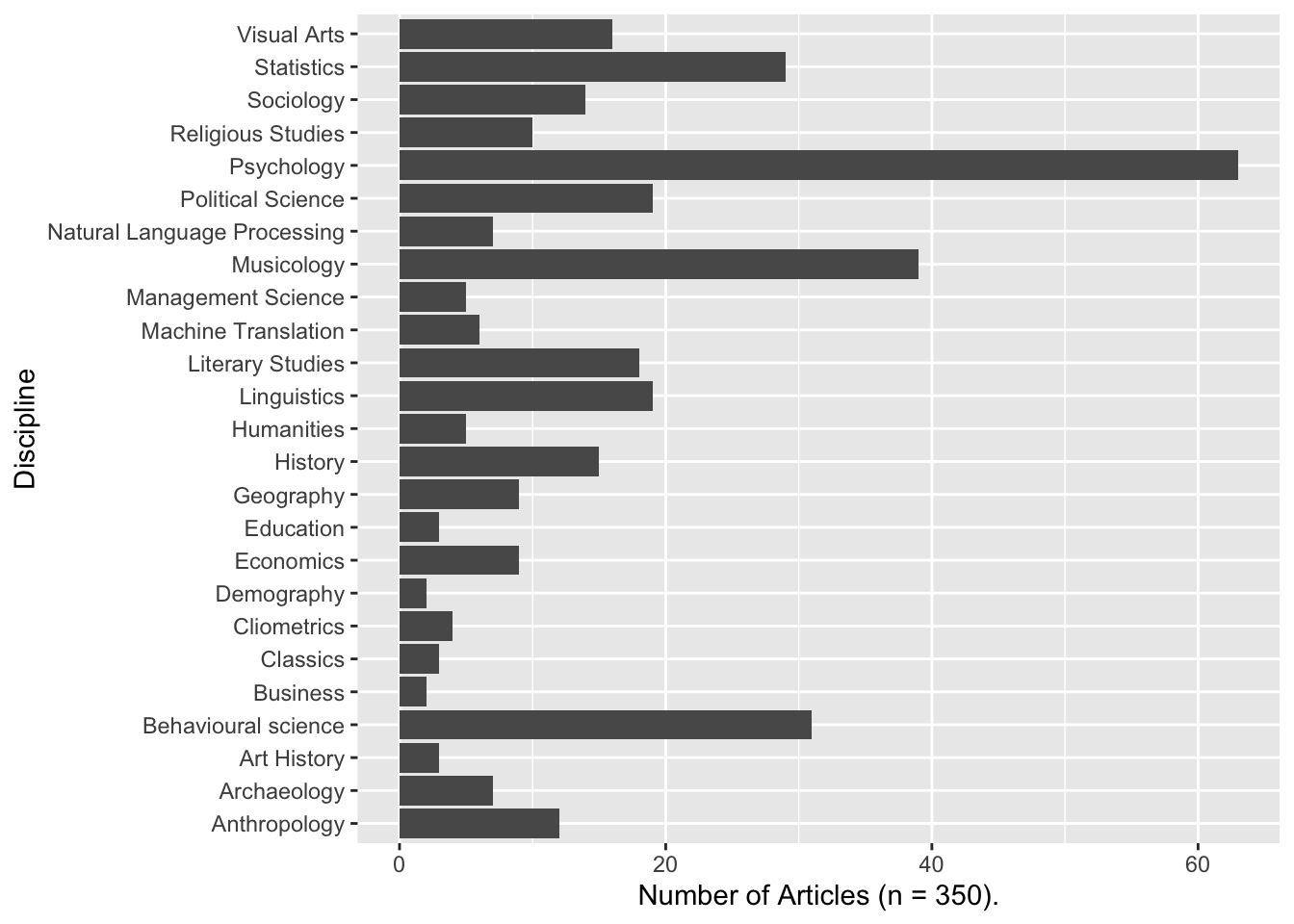
Once we have (very roughly) categorised the tags, we can take a look at the summary statistics. Figure 2 shows the disciplines represented in the corpus. The corpus already suggests new lines of inquiry. The social science disciplines are not so surprising, but it is intriguing to note the presence of many Visual Arts and Musiology articles. These disciplines do not feature heavily in the mainstream historiography of Digital Humanities, which has tended to focus on early efforts in literature and linguistics.
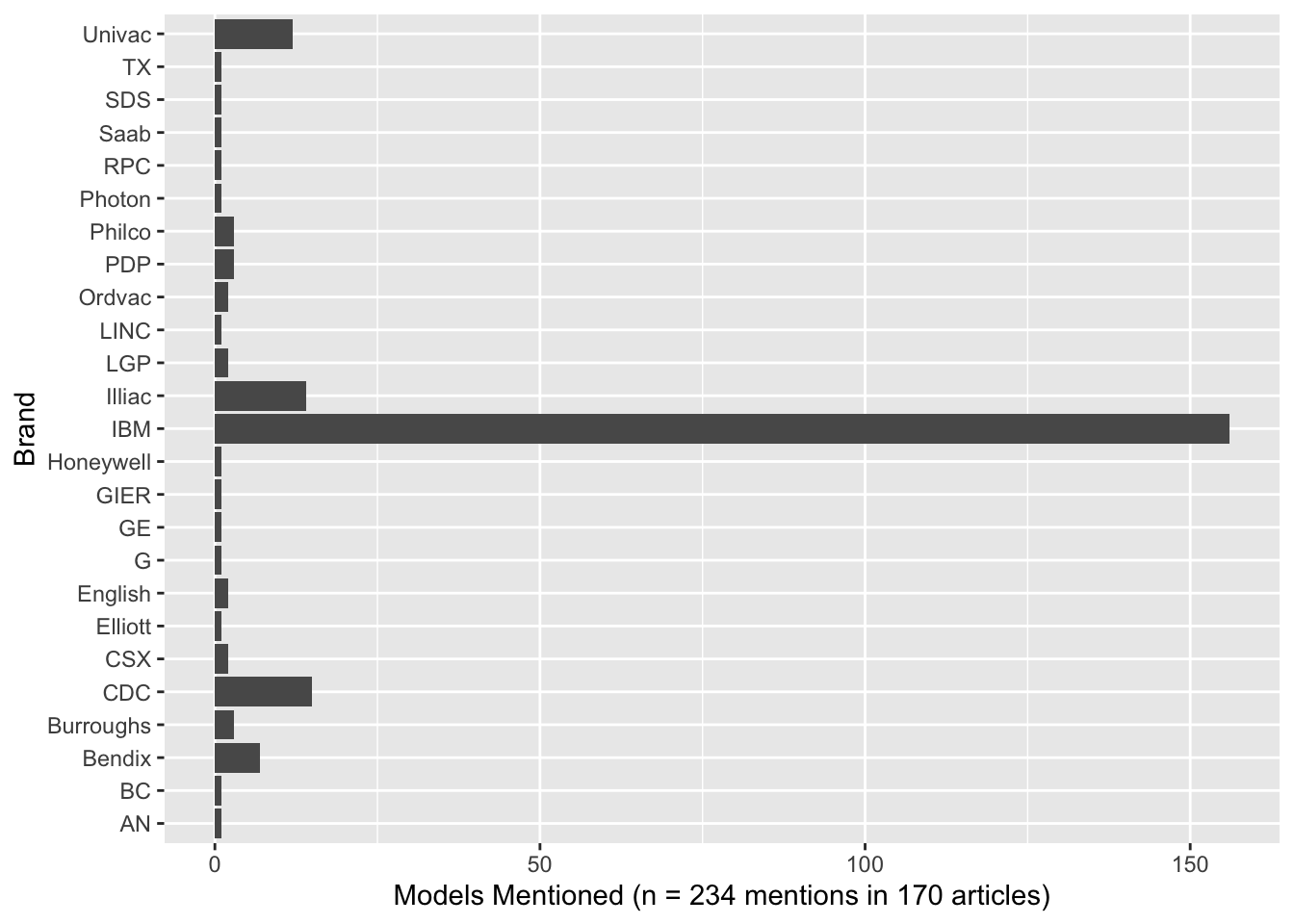
The computer tags also paint an intriguing picture of the early period of CHS. 74 distinct models of computer are mentioned in the corpus—we may find more as we dig deeper. Although there are many models in the corpus, a few big brands or lines of computer dominate, as shown in Figure 3.
Figure 3: Unsurprisingly, IBM dominated the early days of CHS.
Figure 3 will be unsurprisng to readers familiar with the history of computers. IBM was the dominant manufacturer of large computers in this period. By the mid-sixties, mini-computers were becoming more popular, two of the most famous brands being Control Data Corporation (CDC) and Digital Equipment Corporation (who manufactured the PDP line of computers). The Illiac computers present a fascinating case of early use of computation in the Human Sciences. As well as a statistical machine, it was a machine for musical composition, and was used to create the Illiac Suite(Hiller and Baker 1964). You can listen to part of the suite on Spotify:
Where to from here?
Next, we need to tidy up the corpus a bit, and get the text of the articles into R. Then we can get to the meat of the homo calculans project—the discourse of Computational Human Sciences in the 1950s and 60s. What did these early pioneers think they were doing? How did they justify there strange experiments in computational method? I am excited to find out…
Image credit: Alice (Betsy) E. D. Gillies and Donald B. Gillies with the ILLIAC I at the Digital Computer Lab, Urbana Illinois, circa 1958. By SystemBuilder. CC BY-SA 4.0, permalink
References
Hiller, Lejaren A., and Robert A. Baker. 1964. “Computer Cantata: AStudy in CompositionalMethod.”Perspectives of New Music 3 (1): 62. https://doi.org/10.2307/832238.